Introduction
In this blog post, we’ll dive into how to expose Azure AI Foundry endpoints through API Management, protect the APIs from overuse with token-based rate limiting, and monitor token usage per API subscriber. These features in API Management are known as GenAI gateway capabilities.
Azure AI Foundry is a powerful platform for deploying and managing large language models (LLMs) for all sorts of AI-driven applications. These AI capabilities are available via API endpoints. Azure API Management is a platform designed to streamline and enhance the management of APIs, which offers a range of capabilities such as enhanced security, rate limiting, and monitoring etc.
We’ll cover generic LLM policies supported in API Management, equivalent Azure OpenAI policies are available for OpenAI LLM deployment.
High-Level Solution: Integrating API Management with Azure AI Foundry
Here’s the high-level solution
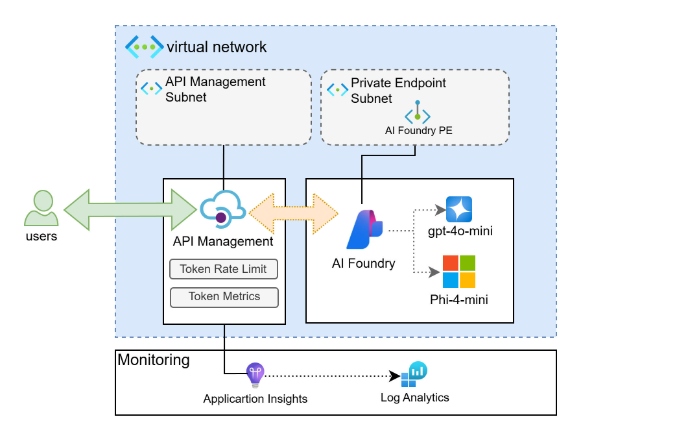
Deployed the Azure AI Foundry service with an AI Hub and an AI project containing all the model deployments. The AI Project has two models: OpenAI gpt-4o-min and Microsoft Phi-4-mini-instruct.
Configured a private endpoint for Azure AI Foundry to a VNet/subnet, making the endpoints accessible only from within the VNet or a peered VNet.
Deployed a private DNS zone to resolve the AI Foundry API hostnames to the private IP address.
Deployed an API Management instance in external mode and connected it to a subnet in the same VNet as the private endpoints (or a subnet in a peered VNet).
Configured the AI project’s inference endpoint as a backend and exposed it as an API in API Management. API Management can handle calls from users and processes them via policies such as authentication/authorization, API rate limiting per subscriber, request/response transformation, etc., securing and protecting backend LLM endpoints.
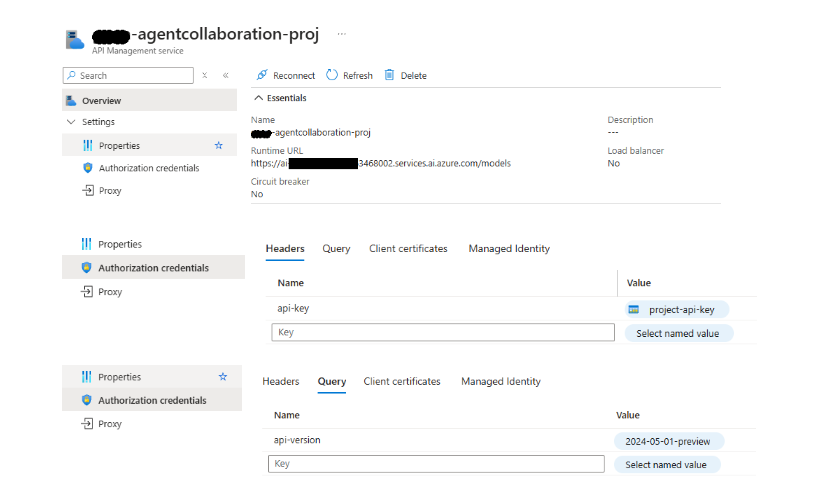 APIM backend configuration
APIM backend configuration
Note: Policies used in this blog are in preview at the time of writing this blog, please refer to the documentation for the latest version and GA llm-token-limit-policy,llm-emit-token-metric-policy.
Managing & Monitoring Token-Based Usage with Policies
Once the integration is set up, we can enforce token-based limits and track token consumption using APIM policies.
1. Token Limit Policy
To prevent excessive LLM usage, implement a Token Limit policy that restricts the number of tokens processed per request:
<inbound>
<set-backend-service id="ai-foundry-project-backend" backend-id="****-agentcollaboration-proj" />
<llm-token-limit tokens-per-minute="50"
counter-key="@(context.Subscription.Id)"
estimate-prompt-tokens="true"
tokens-consumed-header-name="consumed-tokens"
remaining-tokens-header-name="remaining-tokens" />
<base />
</inbound>
This policy limits requests to 50 tokens per minute per subscriber, ensuring fair usage and preventing service overloading.
2. Token Metrics Policy
To gain insights into token usage, use the Token Metrics policy, which logs token consumption for analysis and optimization:
<inbound>
<llm-emit-token-metric namespace="aifoundry">
<dimension name="Client Subscription" value="@(context.Subscription.Id)" />
<dimension name="API ID" value="@(context.Api.Id)" />
</llm-emit-token-metric>
<base />
</inbound>
This policy sends token usage data to the application insight configured in the API management, allowing for real-time monitoring and reporting. This will log custom metric in App Insights with values of Total Tokens, Prompt Token and Completion Token along with the Client Subscription and the API that has used the token.
To support the custom metrics there are two other configurations that are required
Enable Custom Metrics in App Insights.
- Navigate to App Insights > Usage and estimated costs
- Open Custom metrics > Enable “With Dimensions”
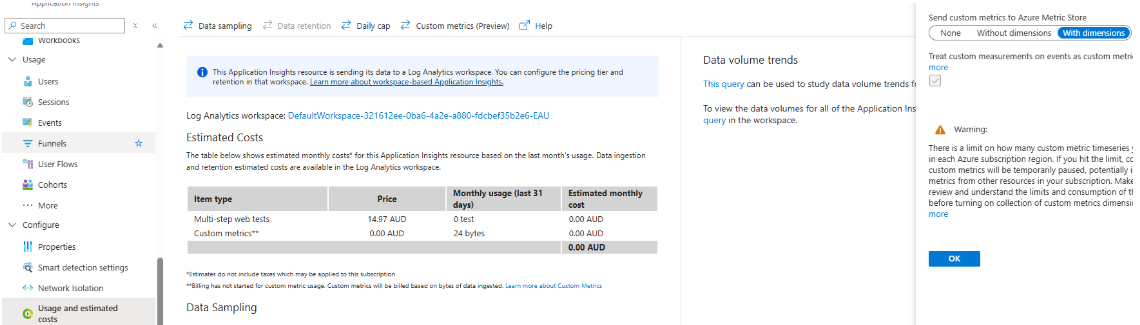
Enable Custom Metrics in API Management API
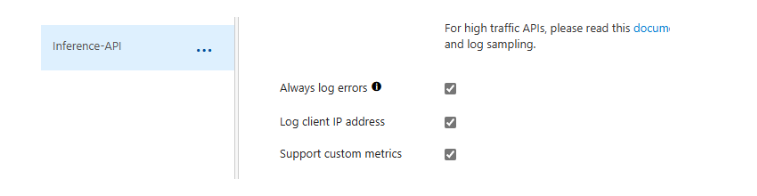
- Navigate to API Management > Select the API > Open Settings
- Check the “Enable custom metrics”
Testing and Validating the Integration
Once the API is configured, validate the setup by:
- Sending test requests using Postman.
- Verifying that the token limits are enforced correctly.
- Checking logs in Azure Monitor to track token consumption and API usage.
- Sending continuous request to the API Management endpoints
Request
POST https://APIM-INSTANCE.azure-api.net/ai/chat/completions
Request Headers
x-api-key: <APIM SUBSCRIPTION>
Content-Type: application/json
Request Body
{
"messages": [
{
"role": "user",
"content": "what are your capabilities?"
}
],
"model": "Phi-4-mini-instruct"
}
Response Headers
Content-Type: application/json
Retry-After: 59
remaining-tokens: 0
Response Body
{ "statusCode": 429, "message": "Token limit is exceeded. Try again in 59 seconds." }
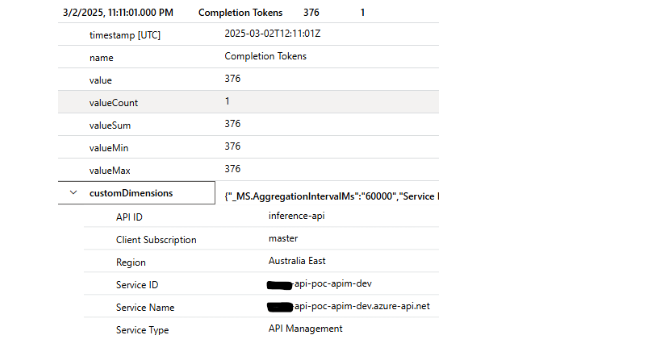
2. Verifying the App Insights logs
Querying the customMetrics table in App Insights gives the following response.
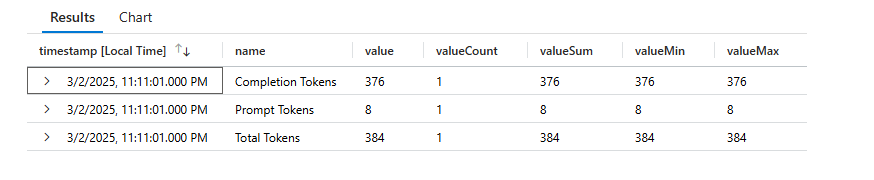
Each entry has custom dimensions as configured in the policy
Conclusion
By integrating Azure AI Foundry inference endpoints with Azure API Management, you can create a secure, and monitored API gateway for all your deployed LLM. The Token Limit policy ensures controlled usage, while the Token Metrics policy provides valuable insights into API consumption. Along with these, other policies like semantic caching, load balancing, and circuit breaking makes API Management a perfect choice to make your AI endpoints more resilient and optimized.
References
Azure AI Model Inference API - Azure AI Foundry | Microsoft Learn
Azure API Management policy reference | Microsoft Learn
GenAI gateway capabilities in Azure API Management | Microsoft Learn